为什么需要微调
我们知道GPT可以通过不断的对话来调整回答的内容、通常我们 prompt 提示词 让他扮演一个角色来回答问题
但是复杂的情况下提示词不足以满足我们的使用条件
比如:让他当一个客服,根据我们系统内部的数据来回答客户的问题。
而我们系统的数据非常的多,不可能每一个问题都列出来跟GPT对话一遍,而且 GPT3.5 版本的最大对话单词是 4097.
超出这个长度会直接报错(This model's maximum context length is 4097 tokens. However, you requested xxx tokens)。所以这个时候我们得上模型微调了
OpenAI 提供了两项基于 GPT-3 模型的能力:
- fine-tune 微调
- embedding 嵌入
embedding 在下一篇文章介绍
fine-tune 模型微调
通过提供以下内容,微调可让您从 API 提供的模型中获得更多收益:
- 比即时设计更高质量的结果
- 能够训练比提示中更多的例子
- 由于更短的提示而节省了代币
- 更低的延迟请求
GPT-3 已经预训练了大量的互联网内容。只需要在 prompt 里写少量的用例,他基本可以感知你的用意,并生成一段基本合理的 completion。这个功能一般叫做 few-shot learning.
fine-tune 基于 few-shot learning,通过训练比写在 prompt 里更多的示例,可以得到更好的结果。模型被微调后,就不用在 prompt 里再写一些实例了。这样可以节省成本和耗时。
使用场景:
- 想让 GPT-3 按照某种格式来识别 Prompt ,或按照某种格式来回答
- 想让 GPT-3 按照某种语气、性格来回答
- 想让 completion 具有某种倾向
比如不进行 fine-tune 提问
prompt:
小红喜欢洋娃娃。小红的性别是?
completion:
女孩,所以她很喜欢洋娃娃。洋娃娃通常有着丰富多彩的服装和装饰,可以让小红玩得很开心。此外,红还可
以给洋娃娃起名字,造出一个属于自己的小世界,从而获得更多的乐趣。GPT 详尽的回答了你的问题,但是可能你只想知道是 男 or 女。
在 prompt 里加入示例
prompt:
示例:小红喜欢洋娃娃。小红的性别是?
答案:女
下面是问题:小明喜欢坦克,小明的性别是?
completion:
答案:男经过提示的 prompt 会按照示例的格式回答你的问题。
训练后的模型中,按照 prompt 格式书写,那么 completion 会自动按照期望的格式返回,而不是返回其他内容.
哪些模型可以微调?
微调目前仅适用于以下基础模型:davinci、curie、babbage和ada。
这些是原始模型,在训练后没有任何说明(例如text-davinci-003)。还可以继续微调微调模型以添加其他数据,而无需从头开始。
- ada :最快、价格最低的模型,适用于简单的分析文本,简单分类,文本修正,关键词搜索等
- babbage :比ada价格、性能高一点的模型,适用于一般类型的分类识别、语义分析等
- curie :性能、功能、价格高于babbage,适用于语言翻译、复杂的分类,情感、总结等
- davinci :功能、性能、价格最高的模型,适用于表达复杂的意图、因果关系分析、创意生成、语义搜
- 索、摘要总结等
模型计费
最新计费可以去官网查看 https://openai.com/pricing
截至 2023-05-29 12:42:54 星期一 微调收费规则如下
| 可微调模型 | 训练费用 | 使用费用 |
|---|---|---|
| Ada | $0.0004 / 1K tokens | $0.0016 / 1K tokens |
| Babbage | $0.0006 / 1K tokens | $0.0024 / 1K tokens |
| Curie | $0.0030 / 1K tokens | $0.0120 / 1K tokens |
| Davinci | $0.0300 / 1K tokens | $0.1200 / 1K tokens |
如何微调
微调顺序
- 准备和上传训练数据
- 训练新的微调模型
- 使用您的微调模型
一个 Python 微调例子
根据官网微调demo,我也创建一个微调的例子
我的环境如下:
- CentOS Linux 7.9
- BT面板
- BT面板安装 python_manager. 并安装Python3.9.7 (因为openai需要Python 3.7.1+ 版本以上)
一、设置python环境
[root@xiadmin ~]# pip3.9
-bash: pip3.9: command not found
[root@xiadmin ~]# pip -V
pip 21.3.1 from /usr/local/lib/python3.6/site-packages/pip (python 3.6)
[root@xiadmin ~]# alias pip3.9='/www/server/python_manager/versions/3.9.7/bin/pip3.9'
[root@xiadmin ~]# pip3.9 -V
pip 21.2.3 from /www/server/python_manager/versions/3.9.7/lib/python3.9/site-packages/pip (python 3.9)
[root@xiadmin ~]# alias python3.9='/www/server/python_manager/versions/3.9.7/bin/python3.9'
[root@xiadmin ~]# python3.9 -V
Python 3.9.7
二、更新 pip
pip3.9 install --upgrade pip三、安装 openai
pip3.9 install --upgrade openai四、配置密钥
# 换成你的 Key
export OPENAI_API_KEY="sk-6688wwwxiadmincom"五、微调的数据
{"prompt":"??##q","completion":" 您好,请问您有什么问题需要咨询呢?我很乐意为您解答end"}
{"prompt":"你好##q","completion":" 亲,您好,非常高兴为您服务,有什么可以为您效劳的呢?end"}
{"prompt":"在吗?##q","completion":" 亲,您好!在的,有什么可以帮您的呢?end"}
{"prompt":"有人?##q","completion":" 您好,您请讲end"}
{"prompt":"客服呢?##q","completion":" 您好,请问您有什么问题需要咨询呢?end"}
{"prompt":"hello##q","completion":" 节日快乐,很高兴为您服务end"}
{"prompt":"hey##q","completion":" 您好,欢迎光临xiadmin.com. 有什么可以为您效劳的呢?end"}
{"prompt":"hi##q","completion":" 亲,在的,有什么可以帮您的呢?end"}
{"prompt":"dd##q","completion":" 亲,在的,非常高兴为您服务,有什么可以帮您的呢?end"}
{"prompt":"滴滴##q","completion":" 您好,欢迎光临xiadmin.com,我将竭诚为您服务。end"}
{"prompt":"老板,你好##q","completion":" 您好,我是xiadmin.com客服,很高兴为您服务,请问有什么我能为您效劳的?end"}保存文件到 /www/wwwroot/GPT/fine-tune/test.jsonl
六、数据格式化
1、设置 openai 到环境变量
ln -s /www/server/python_manager/versions/3.9.7/bin/openai /usr/local/bin/openai2、执行数据检查
openai tools fine_tunes.prepare_data -f /www/wwwroot/GPT/fine-tune/test.jsonl执行效果
[root@xiadmin /]# openai tools fine_tunes.prepare_data -f /www/wwwroot/GPT/fine-tune/test.jsonl
Analyzing...
- Your file contains 11 prompt-completion pairs. In general, we recommend having at least a few hundred examples. We've found that performance tends to linearly increase for every doubling of the number of examples
- All prompts end with suffix `\n\n###\n\n`
- All completions end with suffix `end`
No remediations found.
You can use your file for fine-tuning:
> openai api fine_tunes.create -t "/www/wwwroot/GPT/fine-tune/test.jsonl"
After you’ve fine-tuned a model, remember that your prompt has to end with the indicator string `\n\n###\n\n` for the model to start generating completions, rather than continuing with the prompt. Make sure to include `stop=["end"]` so that the generated texts ends at the expected place.
Once your model starts training, it'll approximately take 2.59 minutes to train a `curie` model, and less for `ada` and `babbage`. Queue will approximately take half an hour per job ahead of you.
[root@xiadmin /]#
3、根据工具提示,进行修改。我的这个没有错误,但是提示样本太少(建议至少有几百个示例。每增加一倍的样本数量,性能就会呈线性增长)。本次主要做测试所以不需理会
根据提示本次11条数据只需训练两分钟,但是得排队半小时...
七、创建微调任务,我使用最贵最强的Davinci开整
执行命令
openai api fine_tunes.create -t "/www/wwwroot/GPT/fine-tune/test.jsonl" -m davinci微调参数说明
| 参数 | 作用 |
|---|---|
| -m | 训练的初始模型 可以选择ada、babbage、curie、davinci或者是你自己通过微调训练的模型名称 |
| -v | 验证文件 验证文件与训练文件具有完全相同的格式,并且您的训练数据和验证数据应该互斥。 |
| --suffix | 命名模型 将最多 40 个字符的后缀添加到经过微调的模型名称中 |
| --n_epochs | 通过调整n_epochs的数量,可以控制模型的训练时期和训练次数,从而影响模型的性能和收敛速度 |
| --batch_size | 默认为 4。较大的 batch_size 可以加快模型的训练速度、模型的稳定性和泛化能力,较小的 batch_size 可以减少内存和计算资源的使用、提高模型在测试数据上的性能。 |
| --learning_rate_multiplier | 默认为 0.05、0.1 或 0.2,具体取决于 final batch_size。可以控制微调训练期间使用的学习率是预训练模型使用的学习率的多少倍。例如,如果您设置为2.0,则微调训练期间使用的学习率将是预训练模型使用的学习率的两倍。微调学习率是用于预训练的原始学习率乘以该乘数。我们建议使用 0.02 到 0.2 范围内的值进行试验,以查看产生最佳结果的值。根据经验,我们发现较大的学习率通常在较大的批量大小下表现更好 |
| --compute_classification_metrics | 默认为False。如果为 True,为了对分类任务进行微调,在每个 epoch 结束时在验证集上计算特定于分类的指标(准确性、F-1 分数等)。 |
八、训练结束,看看效果
一开始以为要等半小时,结果五分钟不到就训练完成了,试试十一条数据的问候语情况
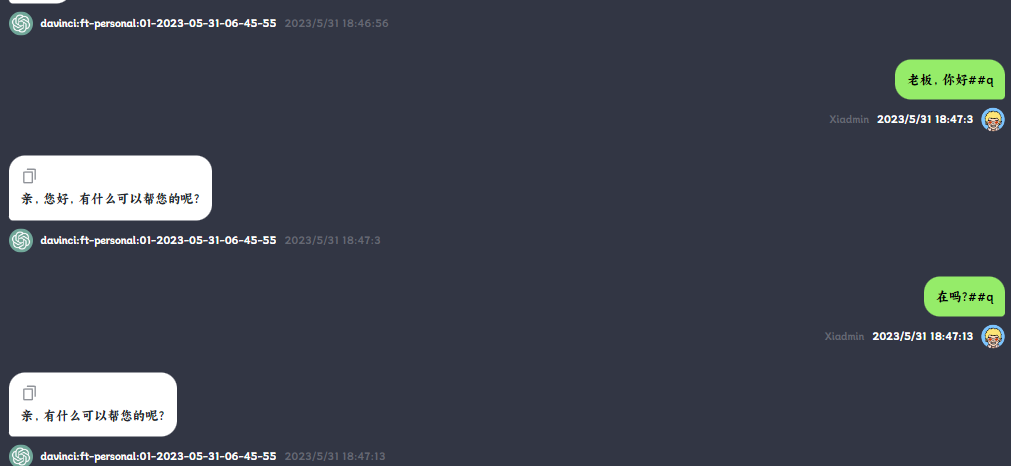
效果还行
总结
- 注意对话的内容分隔符要与训练模型时的一致,我的是
##q与结束符end - top_p 参数调成 1 之后会胡言乱语,我这设置成 0.5 回复正常
- 根据官网提示:提供至少几百个高质量的示例,最好由人类专家审查。从那里开始,性能往往会随着示例数量的每增加一倍而线性增加。增加示例的数量通常是提高性能的最佳和最可靠的方法
