GPT 模型列表
- GPT-4有限的测试版 一套可以理解和生成自然语言或代码的模型,改进自GPT-3.5。【付费,比3.5版本更强】
- GPT-3.5 一套可以理解和生成自然语言或代码的模型,改进自GPT-3。【3.x版本中最强】
- DALL·E 测试版 一个可以根据自然语言提示生成和编辑图像的模型。【图片理解】
- Whisper 测试版 一个将音频转换为文本的模型。【音频识别】
- Embeddings 一组将文本转换为数值形式的模型。
- Moderation 可以检测文本是否可能敏感或不安全的微调模型。
- GPT-3 一套可以理解和生成自然语言的模型。
- Codex 已弃用 一组可以理解和生成代码,并将自然语言翻译成代码的过时模型。【已过时】
3.5 模型
GPT-3.5系列中目前(20230525)最强大的模型是 GPT-3.5-turbo
模型的训练数据截止于2021年9月
GPT-3.5 目前可用模型
| 模型 | 说明 | 最长记忆单词 |
|---|---|---|
| gpt-3.5-turbo | 功能最强大的GPT-3.5型号,优化为聊天,成本为text-davinci-003的1/10 | 4,096 tokens |
| text-davinci-003 | 与curie、babbage或ada模型相比,可以以更好的质量、更长的输出和一致的指令遵循完成任何语言任务。还支持在文本中插入补全。 | 4,096 tokens |
| text-davinci-002 | 类似于text- davincic -003的功能,但使用监督微调而不是强化学习进行训练 | 4,096 tokens |
4.0 模型
3月15日最新GPT-4语言模型,目前我们可以知道的是,4.0 版本比 3.0 版本新增了图片输出识别功能。
我们之前所常见的图片识别功能,如百度AI识图

可以看到百度在GPT-4出来之前都只能做到单一的物品识别,如品牌、植物、动物...
那么GPT-4的识图功能跟他们有什么区别呢,我们看官网示例
示例1
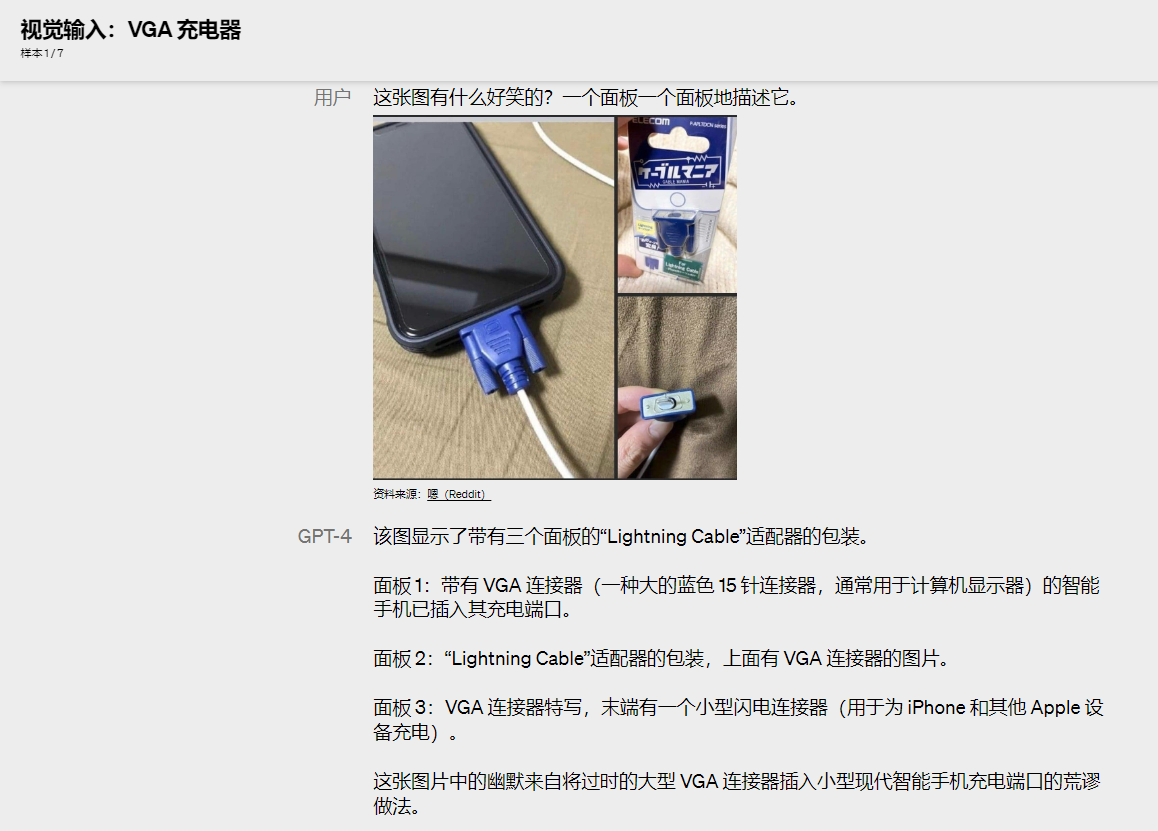
示例2

可以看出 GPT-4 输入一张图,不仅可以识别图片的内容,而且还能分析出图片想表达的意思,在理解了表达的意思之后,还能对内容进行分析,那么拍照答题,图片审核、还有我想起之前做过的一些项目,人脸年龄评测,这些需要对接API的全都可以使用 GPT-4 重新实现,甚至成为一个算命大师,直接拍照识别掌纹,再经过模型的训练输出评测结果.....可谓上至天文下至地府.....
再来看一个 GPT-4 发布会所实现的一个内容。拍照写代码,很多产品喜欢手写设计图给程序员写页面的,这下有完美了hhhh